


Here at Aviron Software, we ❤️ .NET – it’s an amazingly rich platform for backend and web work. (Of course we’re partial to React and React Native as well – both of which play well in the ecosystem!)
Recently, with the explosion of AI and LLMs, we’ve found our clients asking us for more and more AI work – and we’re more than happy to oblige. In fact we’ve delivered a few successful AI projects recently, which our customers loved – get some time on the calendar and we’d love to tell you all about them.
Given that many of our customers are .NET shops originally, we wanted to answer one burning question: can you build AI apps using .NET? Or do you have to (gasp) learn Python?
TLDR: yes you can use .NET all the way down, with a few caveats, mainly around fine-tuning and evaluations… at least, for now.
We’ve built this handy guide for you to help you decide how you want to approach integrating AI into your .NET applications. Follow these handy links to jump to relevant parts of the article.
For making chat completion requests across many types of LLMs including Azure OpenAI and OpenAI, we recommend starting with Microsoft.Extensions.AI and let the complexity of the system reveal itself.
Remember, you don’t always need a comprehensive framework up front. All in all, we’ve found .NET a great platform to build AI apps with.
By the way, you can download many samples from our GitHub that demonstrate a lot of these features. https://github.com/AvironSoftware/dotnet-ai-examples
HTTPS
“HTTPS is all you need”
Let’s start with a somewhat played out “all you need” reference – all you really need at the end of the day is HTTPS. Because HTTPS is the protocol that makes the web go, it makes sense that most of the best models are available via HTTP API.
Like it or not, OpenAI has been so dominant that their (admittedly very well-designed API) has become the defacto standard for interacting with LLMs.
The Chat Completions API is the starting point for most people. https://platform.openai.com/docs/guides/text?api-mode=chat
In particular you should pay attention to the following properties:
model– the property where you choose the LLM model you want to use. I typically stick with gpt-4o or gpt-4o-mini.
messages– this is where you actually send your array of messages to the API. Unlike ChatGPT where you send one message at a time, you will send the entire conversation with each request. Keep in mind that token costs will go up with each additional message.
temperature– the higher the temperature, the higher the creativity, but the more random the output. For most production scenarios I tend to set this low.
tools– where you expose functionality from your application. In other words, you tell OpenAI about the functions within your code, and OpenAI can choose to call them in its response.
A sample request might look like:
{
"model": "gpt-4",
"tools": [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get the current weather for a location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
}
},
"required": [
"location"
]
}
}
}
],
"messages": [
{
"role": "user",
"content": "What's the weather like in Paris today?"
}
]
}
With a sample response coming back from OpenAI looking like:
{
"id": "chatcmpl-abc123",
"object": "chat.completion",
"created": 1677858242,
"model": "gpt-4",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"tool_calls": [
{
"id": "call_1",
"type": "function",
"function": {
"name": "get_weather",
"arguments": "{\n \"location\": \"Paris\"\n}"
}
}
]
},
"finish_reason": "tool_calls"
}
]
}
However, you don’t need to use the API directly in most cases – you can use libraries to help you. Still, it’s always useful to go straight to the API docs to better understand what it is you’re calling and why. We find ourselves spending more time in these docs than any other.
OpenAI’s NuGet package
One option is to use the OpenAI NuGet package directly. There are better abstractions to use as described below (Semantic Kernel and Microsoft.Extensions.AI) but this will certainly get the job done.
Firstly, install the OpenAI NuGet package using the CLI or your favorite .NET IDE:
dotnet add package OpenAI
Defined below is a simple console app demonstrating all of the major parts of the package:
using OpenAI.Chat;
var openAIApiKey = "";
var client = new ChatClient("gpt-4o", openAIApiKey);
var messages = new List<ChatMessage>
{
new SystemChatMessage("You have a Southern accent and are friendly!")
};
Console.WriteLine("Say something to OpenAI!");
while (true)
{
var line = Console.ReadLine();
if (line == "exit")
{
break;
}
messages.Add(new UserChatMessage(line));
var response = await client.CompleteChatAsync(messages);
var chatResponse = response.Value.Content.Last().Text;
Console.WriteLine(chatResponse);
messages.Add(new AssistantChatMessage(chatResponse));
}
In particular:
- The ChatClient is used to authenticate and interact with the Chat Completions API. You simply need the name of the model along with your API key to get started.
- ChatMessage is used to represent your chat messages. In particular:
- SystemChatMessage is used to add a system message to your chat history, to alter the behavior of the
- UserChatMessage is used to represent a message from a user
- AssistantChatMessage is used to represent the response from the API
Note that you’re in charge of making sure your chat history is up to date - see the code sample above. All messages get added back to the chat history manually.
A similar sample also exists for Azure OpenAI:
using System.ClientModel;
using Azure.AI.OpenAI;
using OpenAI.Chat;
Console.WriteLine("Welcome to the Azure OpenAI Test!");
var deploymentName = "";
var endpointUrl = "";
var key = "";
var client = new AzureOpenAIClient(
new Uri(endpointUrl),
new ApiKeyCredential(key)
);
var chatClient = client.GetChatClient(deploymentName);
var messages = new List<ChatMessage>
{
new SystemChatMessage("You have a Southern accent and are friendly!")
};
while (true)
{
Console.WriteLine("Say something to Azure OpenAI please!");
var line = Console.ReadLine();
if (line == "exit")
{
break;
}
messages.Add(new UserChatMessage(line));
var response = await chatClient.CompleteChatAsync(messages);
var chatResponse = response.Value.Content.Last().Text;
Console.WriteLine(chatResponse);
messages.Add(new AssistantChatMessage(chatResponse));
}
The main difference is how you get your chat client – Azure OpenAI uses a slightly different way to create the chat client because individual deployments of OpenAI within Azure can have different properties.
As I mentioned, I wouldn’t tend to use this package directly as there are better abstractions.
Microsoft.Extensions.AI
There’s no doubt that LLMs and AI are changing rapidly and best practices are still being settled. Microsoft itself didn’t codify LLMs into the core libraries of .NET until recently with the release of Microsoft.Extensions.AI.
Things kind of got started with Semantic Kernel, which made abstractions to connect to multiple different kinds of LLMs and to deal with common things most APIs share, including a chat history and a common way of managing tool calls. Recently however, Microsoft decided to make a “base” library for all AI libraries they write going forward – that’s what Microsoft.Extensions.AI was made for.
using Microsoft.Extensions.AI;
using OpenAI;
using ChatMessage = Microsoft.Extensions.AI.ChatMessage;
namespace IntroToMicrosoftExtensionsAI;
public static class ChatClientFactory
{
public static IChatClient CreateChatClient()
{
var openAIApiKey = Environment.GetEnvironmentVariable("OPENAI_API_KEY"); //add your OpenAI API key here
var model = "gpt-4o";
//where the OpenAI client gets built
var client = new OpenAIClient(openAIApiKey);
//where we get our chat client
IChatClient chatClient = client.AsChatClient(model) //NOTE: there is a GetChatClient but that is not the same!
.AsBuilder()
.UseFunctionInvocation()
.Build();
return chatClient;
}
}
var chatClient = ChatClientFactory.CreateChatClient();
var chatHistory = new List<ChatMessage> //NOTE: there is a ChatMessage in OpenAI as well!
{
new (ChatRole.System, "You are a helpful restaurant reservation booking assistant.")
};
Console.WriteLine("Say something to OpenAI and book your restaurant!");
var restaurantPlugin = new RestaurantBookingPlugin();
var chatOptions = new ChatOptions
{
Tools = [
AIFunctionFactory.Create(restaurantPlugin.GetRestaurantsAvailableToBook)
]
};
while (true)
{
var line = Console.ReadLine();
if (line == "exit")
{
break;
}
chatHistory.Add(new ChatMessage(ChatRole.User, line));
var response = await chatClient.GetResponseAsync(chatHistory, chatOptions);
var chatResponse = response.Text;
Console.WriteLine(chatResponse);
chatHistory.Add(new ChatMessage(ChatRole.Assistant, chatResponse));
}
Creating the IChatClient, the base abstraction for all chat interactions using this library, is a little odd. Typically, you start by creating the connection to the AI you’re connecting to (in this case, OpenAI) and then calling AsChatClient on that client to get the IChatClient object.
In other words, OpenAIClient doesn’t directly implement IChatClient – you have to create the base LLM’s client and THEN get the IChatClient abstraction.
Note the weird builder pattern that includes a call to AsBuilder - this wraps around the original IChatClient and allows you to add additional behaviors like tool calling.
//where we get our chat client
IChatClient chatClient = client.AsChatClient(model) //NOTE: there is a GetChatClient but that is not the same!
.AsBuilder()
.UseFunctionInvocation()
.Build();
IChatClient.AsBuilder() allows you to add additional behaviors and properties to IChatClient to support things like tool calling.
ChatHistory is stored as an array/list of ChatMessage and tools are defined inside an array of ChatOptions.
ChatOptions includes things like temperature, tools available, etc. but note that not every LLM will support all of the features.
Semantic Kernel
This is the library that we use most in production because its programming model for tool calls is the most mature.
using IntroToSemanticKernel;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Logging;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.ChatCompletion;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using VectorSearchUsingPostgres;
using ChatMessageContent = Microsoft.SemanticKernel.ChatMessageContent;
var openAIApiKey = Environment.GetEnvironmentVariable("OPENAI_API_KEY");
var model = "gpt-4o";
var postgresContainer = await PostgresContainerFactory.GetPostgresContainerAsync();
var dbContext = postgresContainer.GetDbContext();
//where Semantic Kernel gets built
var semanticKernelBuilder = Kernel.CreateBuilder();
semanticKernelBuilder.Services.AddLogging(l =>
{
l.SetMinimumLevel(LogLevel.Trace);
l.AddSimpleConsole(c => c.SingleLine = true);
});
semanticKernelBuilder.AddOpenAIChatCompletion(model, openAIApiKey);
semanticKernelBuilder.Plugins.AddFromType<RestaurantBookingPlugin>();
semanticKernelBuilder.Services.AddSingleton(dbContext);
Kernel semanticKernel = semanticKernelBuilder.Build();
//where we get our chat client
var chatClient = semanticKernel.GetRequiredService<IChatCompletionService>();
var chatHistory = new ChatHistory(new List<ChatMessageContent>
{
new ChatMessageContent(AuthorRole.System, $"The current date/time in UTC is {DateTime.UtcNow}. You are a helpful restaurant reservation booking assistant.")
});
Console.WriteLine("Say something to OpenAI and book your restaurant!");
while (true)
{
var line = Console.ReadLine();
if (line == "exit")
{
break;
}
chatHistory.Add(new ChatMessageContent(AuthorRole.User, line));
var response = await chatClient.GetChatMessageContentsAsync(
chatHistory,
new OpenAIPromptExecutionSettings
{
FunctionChoiceBehavior = FunctionChoiceBehavior.Auto()
},
semanticKernel
);
var chatResponse = response.Last();
Console.WriteLine(chatResponse);
chatHistory.Add(chatResponse);
}
await postgresContainer.StopAsync();The (somewhat poorly named) Kernel object is the main object that wraps the Semantic Kernel functionality. It’s basically its own dependency injection container that allows you to contain all of your AI-enabled functionality.
One thing they don’t make super clear is that if you want to use an existing DI container (for example, if you’re using ASP.NET Core), you have to call the Kernel constructor directly:
new Kernel(serviceCollection);
Semantic Kernel has a “plugin” model that allows you to define and add tools as normal objects. Want to dig deeper into the Semantic Kernel? Read my blog post on integrating OpenAI and .NET with Semantic Kernel here.
Agentic programming
Agentic AI is not a new concept, but the patterns for developing agentic systems using LLMs are still being worked out.
Between Anthropic’s MCP and a slew of Python libraries designed to handle agentic AI, Python has the upper hand – but functionally speaking it probably doesn’t matter that much. Heck, a Microsoft-sponsored MCP library was published just over a week ago, so we’re definitely catching up! (It’s still in preview, so buyer beware!)
Microsoft has added an agentic-first framework called AutoGen, which (at least for .NET) seems to be lagging behind its .NET counterpart. As of writing the docs are very incomplete for .NET. Further, it’s a Microsoft Research project and all of the signals are that Semantic Kernel will be the production-ready agentic framework of choice, with AutoGen being the more “experimental” library. (Kind of like how F# has fed new important features into C# for ages.)
TLDR: keep a close eye on the MCP SDK as well as Semantic Kernel’s docs for more MCP examples in the next month or two.
Tool Calling
Tool calling is used to expose functionality to the LLM by giving it a set of functions that it can choose to call within a request. This gives you a lot of power when leveraging LLMs by allowing you to connect it to your external system.
Our recommended library for managing tool calls is Semantic Kernel – scroll back up to learn more! You can also do it using Microsoft.Extensions.AI, but Semantic Kernel has a lot more tooling around, well, tool calling.
RAG
RAG – or Retrieval Augmented Generation – is imbuing your prompts with additional data that help the LLM enrich or resolve relevant information based on the user’s request.
For example, if you had an AI system where a user asked a question that the model couldn’t handle on its own, you make a request to a separate system to add context to the initial request so that the LLM could better handle that request.
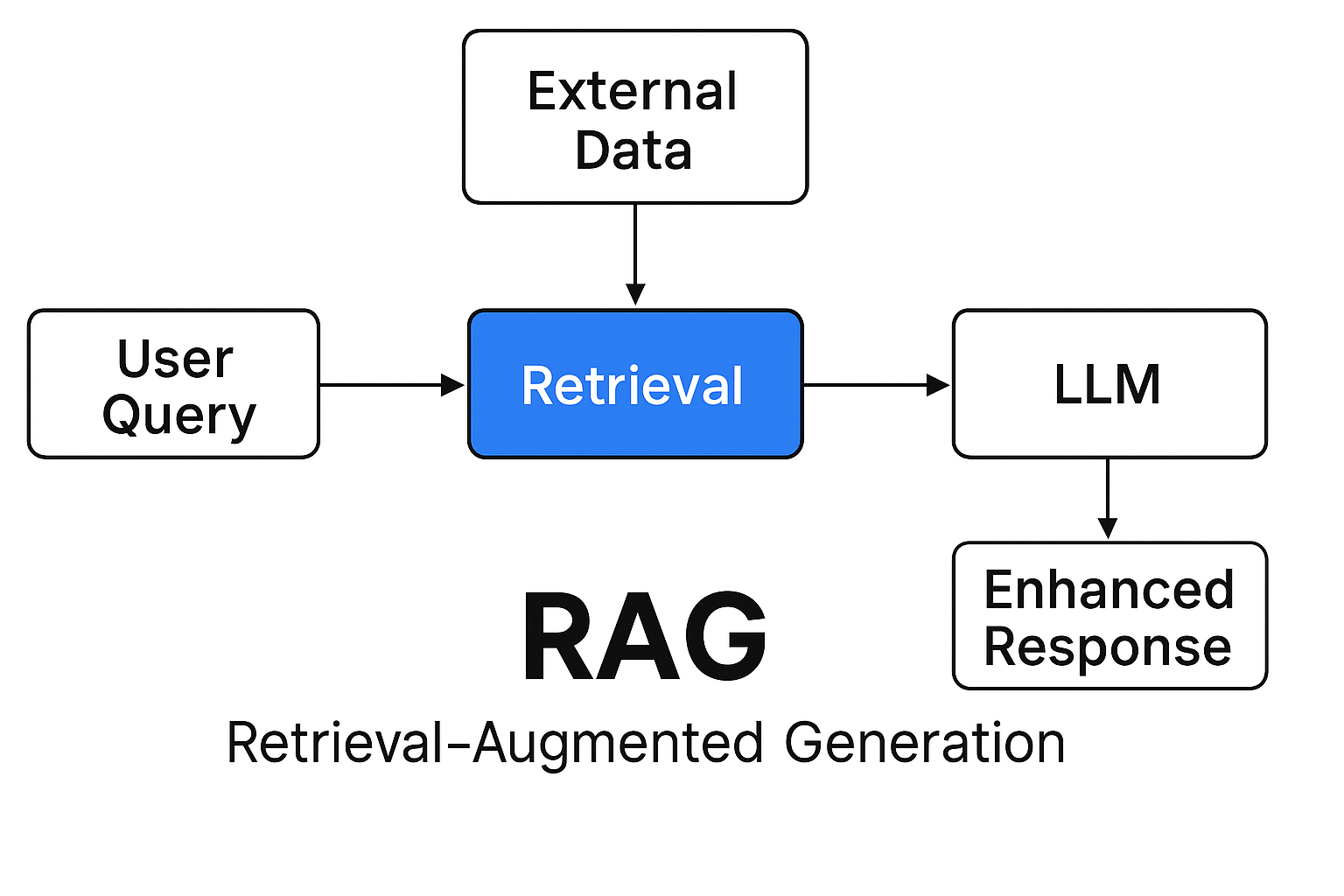
You’d typically use RAG to do things the model could not out of the box. Say for example you wanted to create a chat agent to allow you to ask detailed questions about data within an e-commerce system, like “how many orders included a teddy bear in 2024”. I’d probably solve this problem by using tool calls to do a query to a database, then return that content to the LLM.
Or perhaps you’d handle requests like “what does the employee handbook say about paying out vacation time at the end of employment?” You probably wouldn’t have a tool call that handles that kind of question explicitly, but you might connect the LLM to a system that contains the employee handbook and returns the most relevant information to the LLM to answer the question.
The question about RAG and its place in a .NET world is important, but ultimately is highly sensitive to the use case for your RAG system as RAG systems can get very nuanced, very fast.
Semantic Kernel attempted to make abstractions around RAG in the early days, and I would say those abstractions were a bit misguided – as usual Microsoft attempted to make a “one size fits all” solution as they often tend to do. We attempted to use those abstractions in the early days but had to discard them as we found that we were being limited by them (which goes along with one of Aviron’s philosophies – interfaces are great until they become too limiting – then you should start deleting code!)
We’ve deployed numerous RAG-enabled systems for our clients that went from using tools for RAG (good article by Microsoft here) to embedded search to doing queries using Azure AI search.
It mostly boils down to how you define relevance and how you want to query the data.
For example, we use Postgres a lot, which means using the excellent pgvector extension to store our embeddings. (Embeddings are numerical representations of information and are one of the core concepts that make LLMs work). But you don’t need embeddings – you could also use classic search techniques like BM25 or even a hybrid approach.
There are also services like Azure AI Search that can ingest your documents and give you a good out of the box search experience.
Finally, there’s also Kernel Memory, which is a RAG service that you can separately deploy or even run within your own .NET app. It can store documents in memory for testing and use a backing database in production scenarios. We have a small sample here demonstrating it – run it and ask it a question about the moon!
Bottom line, while there are more libraries for dealing with RAG in Python, you can get very far using .NET before having to invest in learning Python-based tools.
Testing/evals
Truth be told, testing and evals should be WAY closer to the top as there is no way to build a scalable, production-ready AI system without good tests.
In fact, the choice of language isn’t even the first thing you do – it’s defining criteria and a dataset that you can use to determine if the LLM is doing a good job.
When building a chat agent for one of our clients, our job was to make sure that as we incrementally added tools to the system, we didn’t have any major regressions. To that end, we would capture the questions people would ask and then test to see if the correct tool was called and if the tool was invoked with the correct parameters.
For example, if you asked “how many orders included a teddy bear in 2024”, you’d want to know if the tool call properly identified that the user was looking for teddy bears and the start and end date of the request was 1/1/2024 – 12/31/2024.
For the second project, we built a categorization system that had to be highly accurate, so we started by having humans label the problem using our internal tooling, then ran evals that tested lots of different variables (called hyperparameters) such as prompt structure, temperature, and so forth.
Back when we started these projects, we had zero first-party or third-party tools except XUnit. Our goal was delivery, so we did the best we could with what we had – and we were quite successful. We ended up writing out a bunch of unit tests similar to this:
[Theory]
[InlineData("What restaurants are available to book?")]
[InlineData("What restaurants can I book a table at?")]
public async Task Tool_call_is_invoked_successfully(string message)
{
//arrange
var chatClient = ChatClientFactory.CreateChatClient();
var chatHistory = new List<ChatMessage>
{
new (ChatRole.System, "You are a helpful restaurant reservation booking assistant.")
};
var restaurantPlugin = new Mock<IRestaurantPlugin>();
restaurantPlugin.Setup(x => x.GetRestaurantsAvailableToBook()).Returns("Just Bob Evans");
var chatOptions = new ChatOptions
{
Tools = [
AIFunctionFactory.Create(restaurantPlugin.Object.GetRestaurantsAvailableToBook)
],
};
//act
var response = await chatClient.GetResponseAsync(message, chatOptions);
_outputHelper.WriteLine(response.Text);
//assert
restaurantPlugin.Verify(x => x.GetRestaurantsAvailableToBook(), Times.Once);
//do you want to take it this far...?
Assert.Contains("Bob Evans", response.Text);
}
The above code sample is available here along with a fully running example!
However, when we wanted to test beyond tool calls, we gave up and switched to using InspectAI and DeepEval, both open-source Python frameworks, to do the analysis. InspectAI was easier for testing straight inputs/outputs and DeepEval was better for LLM-as-a-judge tests. The choice was easy – when faced with delivering software or spending time building frameworks first, we just decided to go down the beaten path and learn some Python. It worked well for us, but what’s coming for .NET?
Microsoft very quietly released a preview of their evaluation framework for evaluations, calling it (what else?) Microsoft.Extensions.AI.Evaluations. It was so quiet in fact that I didn’t hear about it from pretty much anyone, including others who (like me) have their ear close to the ground on AI from Microsoft. The metrics seem to be based on Azure AI Foundary Evaluations, which as of writing has a Python SDK but not a .NET one (the docs seem to imply a .NET one is in the works). This obviously locks you into using something Azure and not simply .NET, which works for lots of people and not others.
Most .NET devs vastly prefer first-party (e.g. Microsoft-sponsored) support of projects, and most AI systems aren’t built with testing in mind anyways, so the demand for products like this is pretty niche - .NET developers are struggling to know even where to get started.
Regardless, the MOST IMPORTANT takeaway is to remember to ensure you’re doing some kind of testing to ensure your system doesn’t break as you change prompts, add tools, change temperature, change models, etc. Less-than-ideal tests are better than nothing, and systems the can scale to account for (if nothing else) rapid change, need evals.
Fine-tuning
Fine-tuning is the act of customizing an existing foundation model like gpt-4o to your specific use case. To put into perspective how impactful fine-tuning can be – a fine-tuned gpt-4o-mini model can outperform much more powerful models like gpt-4o for your specific use case.
With a couple of exceptions, most of the fine-tuning tooling is either done via web interface (using a service like OpenAI’s fine tuning or using Azure AI Foundry) or Python. There are a couple of fine-tuning libraries available for .NET (one commercially available one called LM Kit that we’ve never tested), but overwhelmingly the tooling is written in Python.
If you find yourself wanting to fine-tune a foundational model, our opinion is that it’s probably worth learning Python right now. More importantly, it’s worth learning about the fundamentals of fine-tuning as well as popular fine-tuning techniques like LoRA.
That said, the general guidelines are to stretch prompt engineering as far as it will go before you decide to invest in fine-tuning. There are lots of specialty cases where it’s worth learning how to fine-tune – reach out to us and we can help you work through those decisions.
Running models locally
LLM services are great and all but what if you want to test other models without sending your data over the web and to a service provider that charges you per token? Running models locally is a great option and is your best way to run certain models. All you need is a sufficiently powerful computer – and the great thing is that many models don’t even require that much. You can get a lot of power even from LLMs that run on far fewer parameters than OpenAI and it also comes built-in with privacy because these models stay contained within your machine and can’t access the Internet. (I’m currently running one on a plane because the wifi is down!)
For running models locally, you don’t need C# or Python – you can use the command line to run ollama directly or use LM Studio.
LM Studio is a GUI tool that allows you to search for open source models on HuggingFace and run them locally. It’s useful because what is normally a little more involved (but still not that complicated) is made easier by a nice GUI tool. However, LM Studio is not licensed for commercial use – you have to reach out to them to get licenses (for a single user, I talked to the CEO and it’s about $20/month – I get the impression that if you buy at volume, it would be significantly lower).
Conclusion
AI isn’t just for Python developers anymore. With the rapid evolution of the .NET ecosystem, thanks to libraries like Microsoft.Extensions.AI, S and robust support for OpenAI and Azure OpenAI, you can build powerful, production-grade AI applications entirely in C#. From simple chat completions to complex agentic systems and RAG architectures, .NET offers the flexibility and performance that modern apps demand.
Of course, there are still areas where Python holds the edge, especially when it comes to fine-tuning and advanced eval frameworks, but that gap is closing fast. The key is to focus on what you're building, not just the tools you’re using. .NET gives you a solid, enterprise-ready foundation to build AI features that are scalable, secure, and aligned with your existing systems.
If you’re thinking about bringing AI into your .NET applications, or want to chat about how we’ve helped other companies do it successfully, we’d love to talk. Grab a time with us, and let’s build something smart, together.

